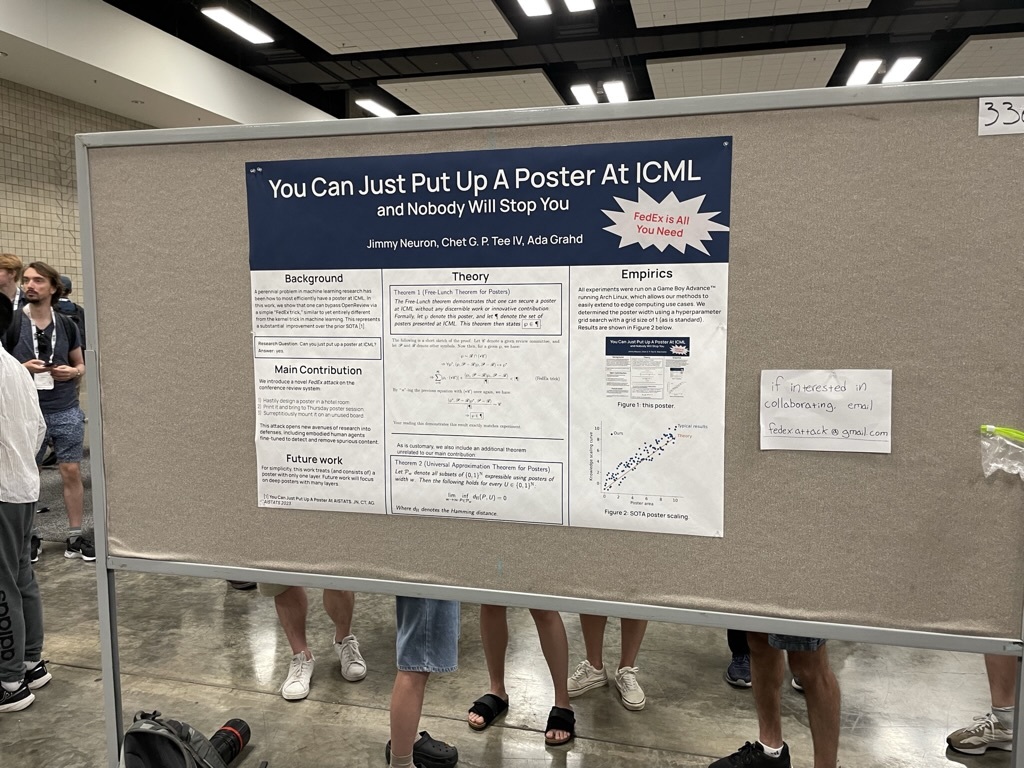
It has come to our attention that the default configuration of Miniconda and conda environments in the user's home directory leads to hitting storage limitations and the dreaded error Disk quota exceeded. We thought we would take some time to guide users in configuring their conda environment directories and package caches to avoid this error and proceed with their research computing.
Conda's config
Software is usually accompanied by a configuration file (aka "config file") or a text file used to store configuration data for software applications. It typically contains parameters and settings that dictate how the software behaves and interacts it's environment. Familiarity with config files allows for efficient troubleshooting, optimization, and adaptation of software to specific environments, like Hyak's shared HPC environment, enhancing overall usability and performance. Conda's config file .condarc, is customizable and lets you determine where packages and environments are stored by conda.
Understanding your Conda
First let's take a look at your conda settings. The conda info command provides information about the current conda installation and its configuration.
The output should look something like this if you have installed Miniconda3.
active environment : None
shell level : 0
user config file : /mmfs1/home/UWNetID/.condarc
populated config files : /mmfs1/home/UWNetID/.condarc
conda version : 4.14.0
conda-build version : not installed
python version : 3.9.5.final.0
virtual packages : __linux=4.18.0=0
__glibc=2.28=0
__unix=0=0
__archspec=1=x86_64
base environment : /mmfs1/home/UWNetID/miniconda3 (writable)
conda av data dir : /mmfs1/home/UWNetID/miniconda3/etc/conda
conda av metadata url : None
channel URLs : https://conda.anaconda.org/conda-forge/linux-64
. . .
package cache : /mmfs1/home/UWNetID/conda_pkgs
envs directories : /mmfs1/home/UWNetID/miniconda3/envs
platform : linux-64
user-agent : conda/4.14.0 requests/2.26.0 CPython/3.9.5 Linux/4.18.0-513.18.1.el8_9.x86_64 rocky/8.9 glibc/2.28
UID:GID : 1209843:226269
netrc file : None
offline mode : False
The paths shown above will show your username in place of UWNetID.
Notice the highlighted lines above showing the absolute path to your config file in your home directory (e.g., /mmfs1/home/UWNetID/.condarc), the directory designated for your package cache (e.g., /mmfs1/home/UWNetID/conda_pkgs), and the directory/directories designated for your environments (e.g., /mmfs1/home/UWNetID/miniconda3/envs). Conda designates directories for your package cache and your environments by default, but under Hyak, your home directory has a 10G storage limit, which can quickly be maxed out by package tarballs and their contents. We can change the location for your package cache and your environments to avoid this.
when you ls your home directory (i.e., ls /mmfs1/home/UWNetID/ or ls ~)you might not see .condarc listed. It might not be there and you might have to create it in the next step, but you already have one, you much use the following command
to list all hidden files (files beginning with .).
Configuring your package cache and envs directories
If you don't have a .condarc in your home directory, you can create and edit it with a hyak preloaded editor like nano or vim. Here we will used nano.
Edit OR ADD the highlighted lines to your .condarc to designate directories with higher storage quotas for our envs_dirs and pkgs_dirs. In this exercise, we will assign our envs_dirs and pkgs_dirs directories to directories in /gscratch/scrubbed/ where we have more storage, although remember scrubbed storage is temporary and files are deleted automatically after 21 days if the timestamps are not updated. Alternatively, your lab/research group might have another directory in /gscratch/ that can be used.
Remember to replace the word UWNetID in the paths below with YOUR username/UWNetID.
Here is what your edited .condarc should look like.
~/.condarc
envs_dirs:
- /gscratch/scrubbed/UWNetID/envs
pkgs_dirs:
- /gscratch/scrubbed/UWNetID/conda_pkgs
always_copy: true
In addition to designating the directories, please include always_copy: true, which is required on the Hyak filesystem for configuring your conda in this way.
After .condarc is edited, we can use conda info with grep to see if our changes have been incorporated.
The result should be something like
/gscratch/scrubbed/UWNetID/conda_pkgs
And for the environments directory
Result
/gscratch/scrubbed/UWNetID/envs
If you don't have the directories you intend to use under your UWNetID in /gscratch/scrubbed/or wherever you intend to designate these directories you will need to create them now for this to work. Use the mkdir command, for example mkdir /gscratch/scrubbed/UWNetID and replace UWNetID with your username. Then create directories for your package cache and envs directory, for example, mkdir /gscratch/scrubbed/UWNetID/conda_pkgs and mkdir /gscratch/scrubbed/UWNetID/envs.
Cleaning up disk storage
After you have reset the package cache and environment directories with your conda config file, you can delete the previous directories to free up storage. Before doing that, you can monitor how much storage was being occupied by each item in your home directory with the command du -h --max-depth=1. Remove directories previously used as cache and envs_dir recursively with rm -r. The following is an example of monitoring storage and removing directories.
rm -r is permanent. We cannot your recover directory. You were warned.
Below is an example output from the du -h --max-depth 1 command
du -h --max-depth=1 /mmfs1/home/UWNetID/
6.7G ./miniconda3/
4.0G ./conda_pkgs
. . .
rm -r /mmfs1/home/UWNetID/miniconda3/envs
du -h --max-depth=1 /mmfs1/home/UWNetID/
2.6G ./miniconda3/
4.0G ./conda_pkgs
. . .
The hyakstorage command is not simultaneously updated. Although you have cleaned up your home directory, hyakstorage might not yet show new storages estimates. du -sh will give you the most up to date information.
Storage can also be managed by cleaning up package cache periodically. Get rid of the large-storage tar archives after your conda packages have been installed with conda clean --all.
Lastly, regular maintenance of conda environments is crucial for keeping disk usage in check. Review you list of conda environments with conda env list and remove unused environments using the conda remove --name ENV_NAME --all command. Consider creating lightweight environments by installing only necessary packages to conserve disk space. For example, create an environment for each project (project1_env) rather than an environment for all projects combined (myenv).
Disk quota STILL exceeded
Be aware that many software packages are configured similarly to conda. Explore the documentation of your software to locate the configuration file and anticipate where storage limitations might become an issue. In some cases, you may need to edit or create a config file for the software to use. pip and R are two other common offenders ballooning the disk storage in your home directory.
Configuring PIP
If you are installing with pip, you might have a pip cache in ~/.cache/pip. Let's locate your the pip config file location under variant "global." You might have to activate a previously built conda environment to do this. For this exercise we will use an environment called project1_env.
conda activate project1_env
(project1_env) $ pip config list -v
. . .
For variant 'user', will try loading '/mmfs1/home/UWNetID/.pip/pip.conf'
. . .
The message "will try loading" rather than listing the config file pip.conf means that a pip config file has not been created. We will create our config file and set our pip cache. Create a directory in your home directory (e.g.,/mmfs1/home/UWNetID/.pip) to hold your pip config file and create a file called pip.conf with the touch command. Remember to also create the new directory for your new pip cache if you haven't yet.
mkdir /mmfs1/home/UWNetID/.pip/
touch /mmfs1/home/UWNetID/.pip/pip.conf
mkdir /gscratch/scrubbed/UWNetID/pip_cache
Open pip.conf with nano or vim and add the following lines to designate the location of your pip cache.
[global]
cache-dir=/gscratch/scrubbed/UWNetID/pip_cache
Check that your pip cache has been designated.
(project1_env) $ pip config list
/mmfs1/home/UWNetID/.pip/pip.conf
(project1_env) $ pip cache dir
/gscratch/scrubbed/UWNetID/pip_cache
Configuring R
We previously covered this in our documentation. Edit or create a config file called .Renviron in your home directory. Use nano or vim to designate the location of your R package libraries. The contents of the file should be something like the following example.
~/.Renviron
R_LIBS="/gscratch/scrubbed/UWNetID/R/"
The directory designated by R_LIBS will be where R installs your package libraries.
I'm still stuck
Please reach out to us by emailing help@uw.edu with "hyak" in the subject line to open a help ticket.
Several users noticed some idiosyncrasies when configuring conda to better use storage on Hyak. In short, by default miniconda3 uses softlinks to help preserve storage, storing one copy of essential packages (e.g., encodings) and using softlinks to make the single copy available to all conda environments. On Hyak, which utilizes a mounted filesystem server, these softlinks were broken, leading to broken environments after their first usage. We appreciate the help of the Miniconda team who helped us find a solution. More details about this can be found by following this link to the closed issue on Github.